Java ConcurrentHashMap - 동시성 제어의 이해
최근 면접을 준비하며 자료구조와 스레드, 동시성 등을 공부하면서 멀티스레드 환경에서의 데이터 처리에 대해 이해하고자 관심을 갖게 되었다. 특히 여러 스레드가 동시에 접근하는 Java에서는 데이터 구조를 다룰 때 더욱 각별한 주의가 필요하다. 이러한 문제를 해결하기 위해 등장한 Java의 ConcurrentHashMap의 내부 동작에 대해 자세히 알아보려 한다.
1. 들어가며
필자가 이전에 작성한 ConcurrentHashMap을 통한 멀티스레드 환경 및 동시성 제어 알아보기에서 보다 코드 중심적으로 풀어보려 한다.
2. HashMap의 동시성 문제
2.1. 기본적인 동시성 문제
먼저 일반적인 HashMap이 멀티스레드 환경에서 발생시키는 문제를 먼저 살펴보자. 여러 스레드가 동시에 put 연산을 수행할 경우, 예상치 못한 결과가 발생할 수 있다.
// HashMap의 동시성 문제 예시
Map<String, Integer> hashMap = new HashMap<>();
// Thread 1
hashMap.put("key", 1);
// Thread 2
hashMap.put("key", 2);
2.2. 실제 발생 가능한 문제점
이러한 동시성 문제는 실제 운영 환경에서 데이터 정합성을 해치는 심각한 버그로 이어질 수 있다. 다음은 실제 발생할 수 있는 문제 상황이다.
public class UserSessionManager {
private static final Map<String, UserSession> sessions = new HashMap<>();
public static void login(String userId, UserSession session) {
// 동시에 여러 스레드가 같은 userId로 로그인을 시도하는 경우
if (!sessions.containsKey(userId)) { // Thread 1, Thread 2 모두 이 조건을 통과할 수 있음
sessions.put(userId, session); // 마지막 스레드의 세션만 저장됨
}
}
public static UserSession getSession(String userId) {
return sessions.get(userId);
}
}
이 코드에서 발생할 수 있는 문제들은 다음과 같다:
- 데이터 손실: 두 사용자가 동시에 로그인할 때, 한 사용자의 세션 정보가 손실될 수 있다.
- 메모리 누수: 이전 세션이 제대로 정리되지 않아 메모리 누수가 발생할 수 있다.
- 보안 취약점: 다른 사용자의 세션으로 잘못 교체되어 보안 문제가 발생할 수 있다.
실제 운영 환경에서는 이러한 문제가 더욱 심각한 결과를 초래할 수 있다:
public class OrderProcessor {
private static final Map<String, Integer> inventory = new HashMap<>();
public static boolean processOrder(String productId, int quantity) {
Integer currentStock = inventory.get(productId);
if (currentStock >= quantity) { // Thread 1, Thread 2 모두 재고가 충분하다고 판단
// 실제로는 두 스레드의 주문 수량 합이 재고를 초과할 수 있음
inventory.put(productId, currentStock - quantity);
return true;
}
return false;
}
}
이 경우 발생할 수 있는 문제점들은 다음과 같다.
- 재고 관리 오류: 실제 재고보다 더 많은 주문이 처리될 수 있다.
- 데이터 불일치: 재고 수량이 마이너스로 떨어질 수 있다.
- 비즈니스 로직 오류: 잘못된 재고 정보로 인해 잘못된 비즈니스 결정이 내려질 수 있다.
이러한 문제들을 해결하기 위해 ConcurrentHashMap은 다음과 같은 방식으로 사용할 수 있다.
public class SafeOrderProcessor {
private static final ConcurrentHashMap<String, Integer> inventory
= new ConcurrentHashMap<>();
public static boolean processOrder(String productId, int quantity) {
return inventory.replace(productId,
inventory.get(productId),
inventory.computeIfPresent(productId, (key, value) ->
value >= quantity ? value - quantity : value));
}
}
3. ConcurrentHashMap의 해결책
3.1. 기본 구조
Oracle의 공식 문서에 ConcurrentHashMap은 동시성 컬렉션의 대표적인 예시로, synchronized 컬렉션과는 다른 방식으로 동시성을 보장한다. ConcurrentHashMap은 내부적으로 세그먼트(Segment)라는 독립적인 해시 테이블로 구성된다. 각 세그먼트는 자신만의 락을 가지고 있어, 다른 세그먼트에 대한 작업과 독립적으로 동작한다. Java 8 이전에는 세그먼트 수가 기본값 16으로 설정되어 있었으나, Java 8부터는 Node 배열을 사용하는 방식으로 변경되어 더 효율적인 동시성 제어가 가능해졌다.
public class ConcurrentHashMap<K, V> {
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
private final Segment<K, V>[] segments;
// ...
}
세그먼트의 개수는 성능에 직접적인 영향을 미친다. Brian Goetz의 “Java Concurrency in Practice”에 따르면, 세그먼트 수는 예상 동시 스레드 수의 두 배로 설정하는 것이 최적의 성능을 보인다고 한다.
3.2 세그먼트 락킹의 장점
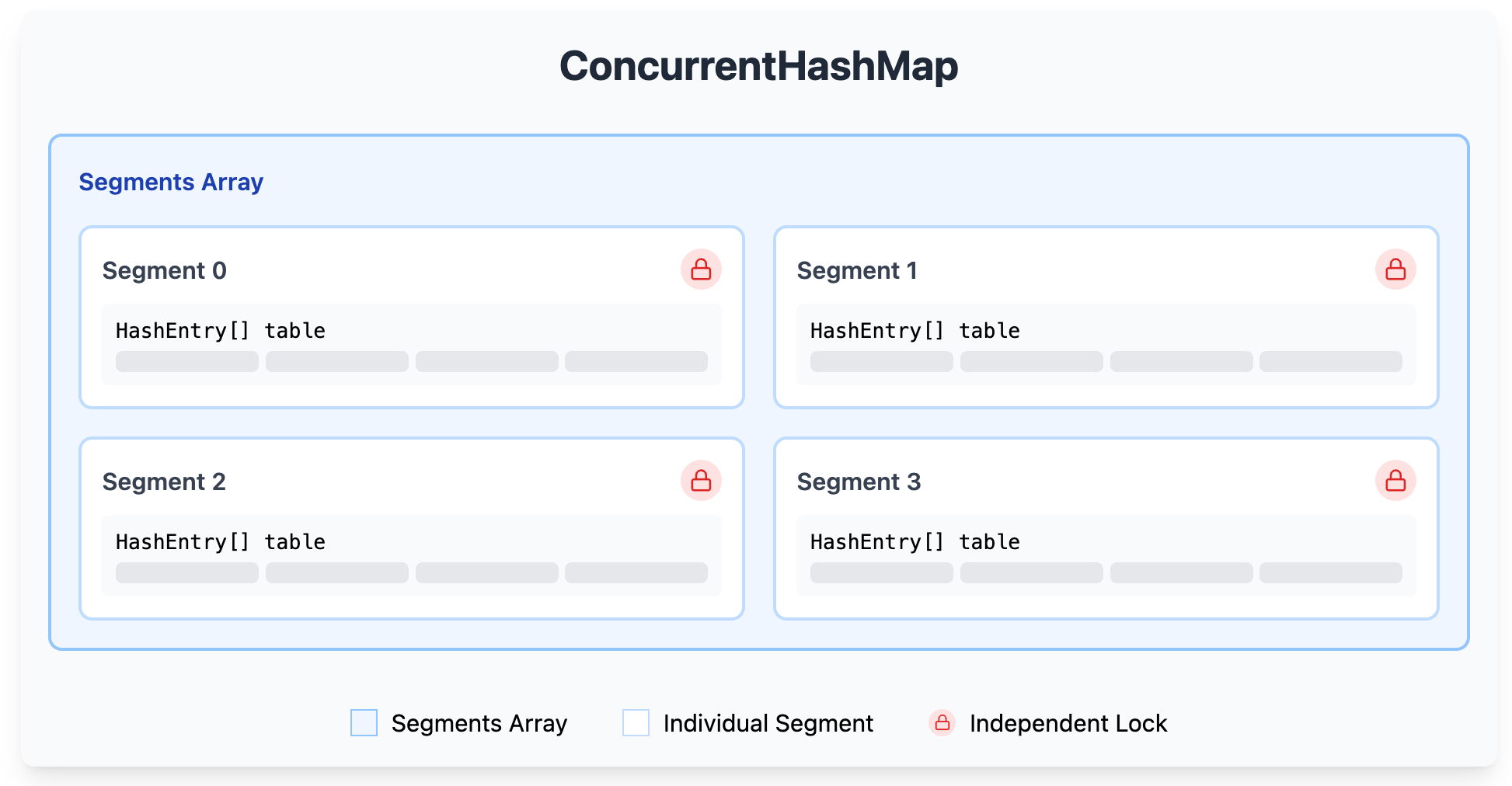
세그먼트 락킹은 하나의 큰 금고를 여러 개의 작은 금고로 나누는 것과 같다. 각각의 작은 금고는 독립적으로 접근이 가능하며, 이는 전체 시스템의 처리량을 향상시킬 수 있다.
세그먼트 락킹의 주요 장점은 다음과 같다.
세밀한 락 제어
- 전체 맵이 아닌 특정 세그먼트만 락을 획득한다
- 다른 세그먼트의 읽기/쓰기 작업은 차단되지 않는다
향상된 동시성
- 검색 작업에서는 락을 사용하지 않는다
- 업데이트 작업에서도 최소한의 락만 사용한다
확장성
- 멀티스레드 환경에서 synchronized HashMap보다 더 나은 확장성을 제공한다
- 동시 접근이 많은 상황에서 더 효율적이다
다만 다음과 같은 특성을 고려해야 한다.
- 단일 스레드 환경에서는 synchronized 컬렉션보다 오버헤드가 발생할 수 있다
- “concurrent” 컬렉션은 단일 락으로 전체 컬렉션을 보호하지 않는다
- 완전한 동기화가 필요한 경우에는 synchronized 컬렉션이 더 적합할 수 있다
4. 동시성 제어 메커니즘 상세 분석
4.1 ReentrantLock과 lock() 메서드의 동작 원리
ConcurrentHashMap은 내부적으로 ReentrantLock을 사용하여 동시성을 제어한다. ReentrantLock은 ‘reentrant(재진입 가능한)’이라는 이름처럼 동일 스레드에서 중첩하여 락을 획득할 수 있는 특징을 가진다. 이는 synchronized 키워드와 비교하여 명시적인 락 획득/해제가 필요하며, 더 세밀한 제어가 가능하다.
public class Segment<K,V> extends ReentrantLock {
private static final long serialVersionUID = 2249069246763182397L;
transient volatile HashEntry<K,V>[] table;
transient int count;
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 락 획득 시도
lock();
try {
int c = count;
if (c++ > threshold) // 임계값 초과 시 리해시
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1); // 해시 인덱스 계산
HashEntry<K,V> first = tab[index];
// 키가 이미 존재하는지 확인
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) { // 기존 키가 존재하는 경우
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
} else { // 새로운 엔트리 추가
oldValue = null;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // 카운트 증가
}
return oldValue;
} finally {
unlock(); // 락 해제 보장
}
}
}
위 코드에서 주목할 점은 다음과 같다.
lock()호출로 세그먼트에 대한 배타적 접근 획득try-finally블록으로 락 해제 보장- 해시 충돌 시 연결 리스트 방식으로 처리
volatile변수를 통한 메모리 가시성 보장
CAS(Compare-And-Swap) 연산과 메모리 가시성
ConcurrentHashMap의 동시성 제어에서 핵심이 되는 것은 CAS 연산이다. CAS는 다음과 같이 동작한다.
- 현재 값을 읽는다
- 예상 값과 비교한다
- 일치하면 새 값으로 교체한다
- 일치하지 않으면 실패한다
이는 volatile 키워드와 함께 사용되어 메모리 가시성을 보장한다. volatile은 다음을 보장한다.
- 변수의 읽기/쓰기가 원자적으로 수행된다
- 캐시된 값이 아닌 항상 최신 값을 읽는다
- 변수 접근 전후의 코드 재배치가 방지된다
예를 들어, 다음과 같은 상황에서
volatile int count = 0;
// Thread 1
count++;
// Thread 2
System.out.println(count);
Thread 2는 항상 증가된 값을 볼 수 있다.
4.2 락의 내부 구현과 상태 관리
ReentrantLock의 내부에서는 AbstractQueuedSynchronizer(AQS)를 사용하여 락의 상태를 관리한다.
public class ReentrantLockInternals {
private static final int SYNC_STATE_BITS = 16;
private volatile int state; // 락의 재진입 횟수를 추적
private transient Thread owner; // 현재 락을 보유한 스레드
final void lock() {
if (compareAndSetState(0, 1)) { // CAS로 락 획득 시도
setOwner(Thread.currentThread());
} else {
acquire(1); // 락 획득 실패 시 대기 큐에 진입
}
}
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) { // 락이 해제된 상태
// 공정성 정책에 따라 락 획득 시도
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setOwner(current);
return true;
}
} else if (current == getOwner()) { // 재진입 시도
int nextc = c + acquires;
setState(nextc);
return true;
}
return false;
}
// 대기 큐 관리를 위한 노드 클래스
static final class Node {
volatile Node prev;
volatile Node next;
volatile Thread thread;
Node(Thread thread) {
this.thread = thread;
}
}
}
이 구현 코드(간소화된 버전)의 주요 특징은 다음과 같다.
- state 변수로 락의 재진입 횟수 관리
- CAS 연산으로 락 획득 시도
- 대기 큐를 통한 공정성 보장
- volatile 키워드로 메모리 가시성 보장
4.3 세그먼트 락킹 전략
ConcurrentHashMap은 여러 세그먼트로 분할하여 락킹을 수행한다.
public class ConcurrentHashMapSegments<K,V> {
// 세그먼트 배열
final Segment<K,V>[] segments;
static final class Segment<K,V> extends ReentrantLock {
static final float DEFAULT_LOAD_FACTOR = 0.75f;
volatile transient int count;
int threshold;
volatile transient HashEntry<K,V>[] table;
// 세그먼트 크기 조정
final void rehash() {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity >= MAXIMUM_CAPACITY)
return;
// 새로운 테이블 생성 및 데이터 이전
HashEntry<K,V>[] newTable =
HashEntry.newArray(oldCapacity << 1);
int sizeMask = newTable.length - 1;
// 락을 보유한 상태에서 데이터 이전
for (int i = 0; i < oldCapacity; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
do {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
e.next = newTable[idx];
newTable[idx] = e;
e = next;
} while (e != null);
}
}
table = newTable;
}
}
// 세그먼트 인덱스 계산
private int segmentFor(int hash) {
return (hash >>> segmentShift) & segmentMask;
}
}
이 소스 코드의 특징은 다음과 같다.
- 각 세그먼트가 독립적인 락을 가짐
- 해시값을 기반으로 세그먼트 선택
- 동적 크기 조정(rehash)시에도 락 유지
- 세그먼트 단위의 독립적인 임계값 관리
4.4 조건 변수(Condition)를 활용한 대기/통지
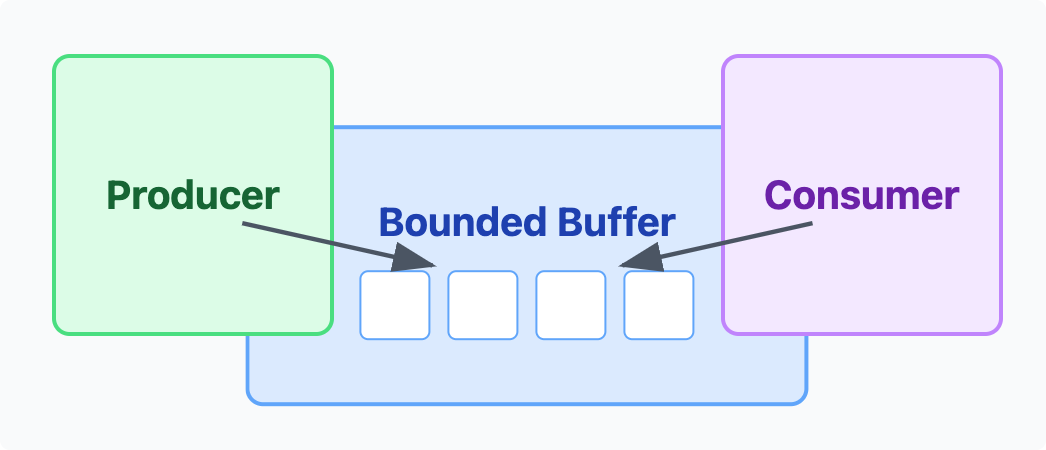
ReentrantLock은 Condition을 통해 보다 더 세밀한 스레드 제어가 가능하다. 필자는 이를 활용한 ‘Producer & Consumer 패턴’ 구현에 대한 예제 코드를 작성해보았다.
public class BoundedBuffer<E> {
private final ReentrantLock lock = new ReentrantLock();
private final Condition notFull = lock.newCondition();
private final Condition notEmpty = lock.newCondition();
private final E[] items;
private int putPtr, takePtr, count;
@SuppressWarnings("unchecked")
public BoundedBuffer(int capacity) {
items = (E[]) new Object[capacity];
}
public void put(E x) throws InterruptedException {
lock.lock();
try {
while (count == items.length)
notFull.await(); // 버퍼가 가득 찼을 때 대기
items[putPtr] = x;
putPtr = (putPtr + 1) % items.length;
count++;
notEmpty.signal(); // 대기 중인 소비자에게 알림
} finally {
lock.unlock();
}
}
public E take() throws InterruptedException {
lock.lock();
try {
while (count == 0)
notEmpty.await(); // 버퍼가 비었을 때 대기
E x = items[takePtr];
takePtr = (takePtr + 1) % items.length;
count--;
notFull.signal(); // 대기 중인 생산자에게 알림
return x;
} finally {
lock.unlock();
}
}
}
조건 변수 사용 시 주의해야 할 중요한 현상 중 하나는 ‘spurious wakeup’이다. 이는 조건이 만족되지 않았음에도 스레드가 깨어나는 현상으로, 다음과 같이 방지할 수 있다.
- while문을 사용한 조건 재확인
- 상태 변경 시 명시적인 signal() 호출 3.타임아웃을 활용한 대기 시간 제한
실제 운영 환경에서는 다음과 같은 최적화가 가능하다.
- 짧은 대기 시간이 예상되는 경우 spinlock 활용
- 조건 변수 대신 CountDownLatch나 Semaphore 사용 고려
- 대기 큐의 크기를 모니터링하여 성능 튜닝
4.5 타임아웃과 인터럽트 처리
락 획득 시 타임아웃이나 인터럽트 처리는 다음과 같이 구현할 수 있다.
public class TimeoutExample {
private final ReentrantLock lock = new ReentrantLock();
public boolean performOperation() {
try {
// 2초 동안만 락 획득 시도
if (lock.tryLock(2, TimeUnit.SECONDS)) {
try {
// 임계 영역 코드
return true;
} finally {
lock.unlock();
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return false;
}
public void interruptibleOperation() throws InterruptedException {
// 인터럽트 가능한 락 획득
lock.lockInterruptibly();
try {
// 임계 영역 코드
} finally {
lock.unlock();
}
}
}
5. 결론
필자는 ReentrantLock과 ConcurrentHashMap의 동시성 제어 메커니즘이 다음과 같은 이점을 제공한다고 생각한다.
- 세밀한 락 제어를 통한 성능 최적화
- 명시적인 락 관리로 인한 더 나은 가독성
- 조건 변수를 통한 유연한 스레드 조정
- 타임아웃과 인터럽트 처리 기능
하지만 이러한 기능들을 효과적으로 활용하기 위해서는 다음 사항들을 고려하여 설계하여야 한다.
- 락의 범위를 최소화하여 경합 감소
- 데드락 방지를 위한 락 획득 순서 관리
- 적절한 타임아웃 설정으로 시스템 안정성 확보
- 성능 모니터링을 통한 지속적인 최적화
이러한 고려사항들을 바탕으로 구현하면, 안정적이고 효율적인 동시성 애플리케이션을 개발할 수 있을 것이다.
6. 참고자료
- Java SE 11 ConcurrentHashMap Documentation
- Java SE 11 ReentrantLock Documentation
- DZone - Understanding the Java ConcurrentHashMap
- Brian Goetz, “Java Concurrency in Practice”, Addison-Wesley Professional, 2006